Compute Platform
Namespace provides fast, reliable, and secure compute infrastructure designed for modern development needs. Whether you're building for mobile, web, desktop, or the cloud, our cross-platform support and high-performance hardware ensure that you can develop, test, and deploy with confidence.
We deploy our own hardware to our own racks and manage our own networking. This level of vertical integration allows Namespace to provide higher consistency, faster performance and a better price.
Why Namespace?
Platforms
Run Linux on your choice of modern CPU architecture. Namespace supports both AMD64 and ARM64 workloads on high-end processors, with shape options tuned for CI, container builds, and parallel compute.
macOS instances run on Apple M4 Pro or M5 Max processors, delivering native Apple Silicon performance with builtin support for the complete Apple development ecosystem, including Xcode, iOS, and Metal.
Namespace also offers Windows instances, using the same AMD EPYC processors that power our Linux environments.
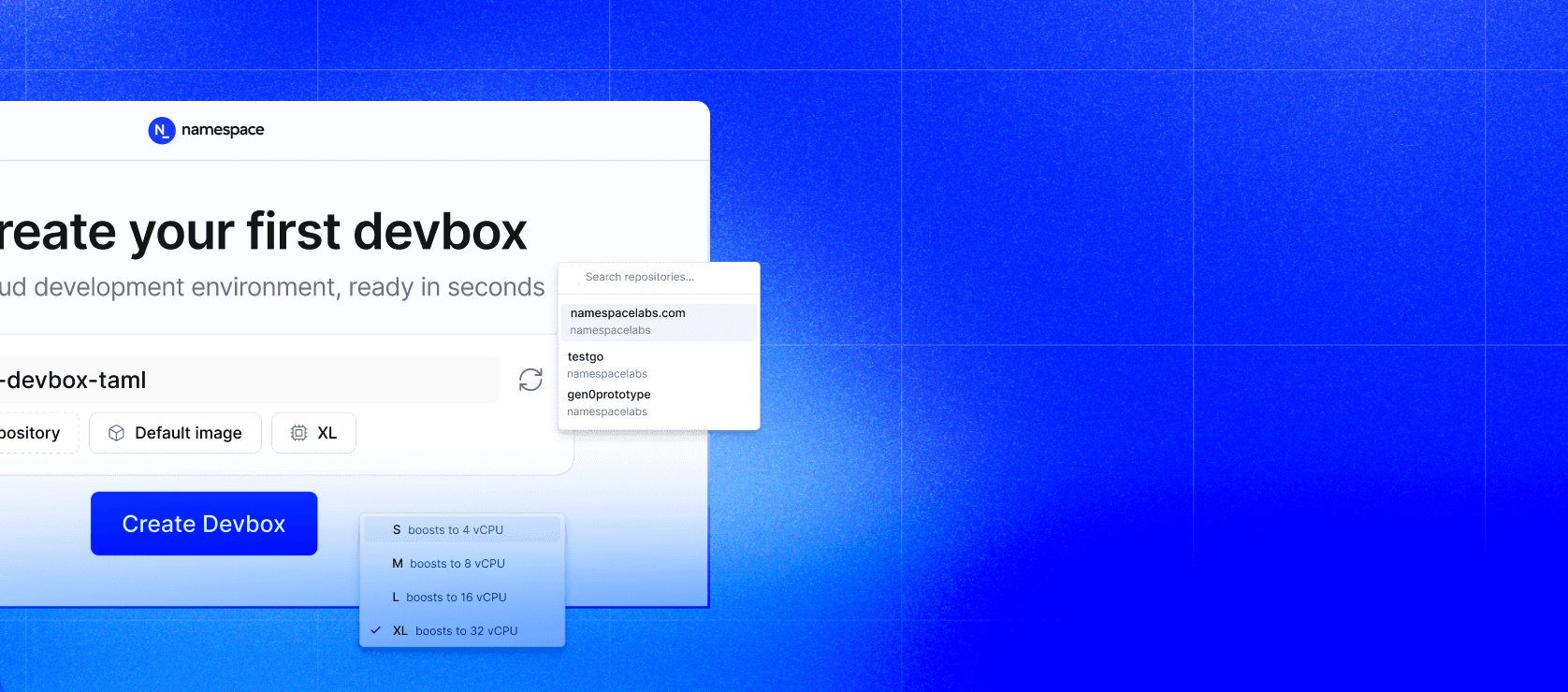
Get started on Namespace Compute
Compute Features
Observability → Monitor your compute instances with comprehensive metrics, logs, and performance insights.
SSH & Remote Display → Access your instances remotely via SSH, web terminals, and VNC for graphical applications.
Machine Shapes → Explore supported CPU and memory configurations optimized for your workload requirements.
Nested Virtualization → Check where nested virtualization and KVM are available across platforms and architectures.
Resource Limits → Understand platform limits and multi-tenant resource management.